

- Почему краулер не индексирует все страницы сайта сразу
- Crawlspider¶
- Правила сканирования¶
- Csvfeedspider¶
- Пример CSVFeedSpider¶
- Scrapy.spider¶
- Xmlfeedspider¶
- Пример XMLFeedSpider¶
- Аргументы паука¶
- Вежливые и вредные роботы
- Зачем поисковые роботы притворяются реальными пользователями
- Как работает робот google и «яндекса»
- Как часто обновляется индекс google и «яндекса»
- Пример crawlspider¶
- Пример csvfeedspider¶
- Пример xmlfeedspider¶
- Примеры sitemapspider¶
- Ссылки
- Универсальные пауки¶
- Фактор роботности
Почему краулер не индексирует все страницы сайта сразу
У каждого поискового робота существует собственный лимит по числу обращений к сайту — например, суточный
— краулинговый бюджет. В Google Search Console
можно посмотреть суммарное количество запросов сканирования вашего сайта на вкладке «Статистика
сканирования»:
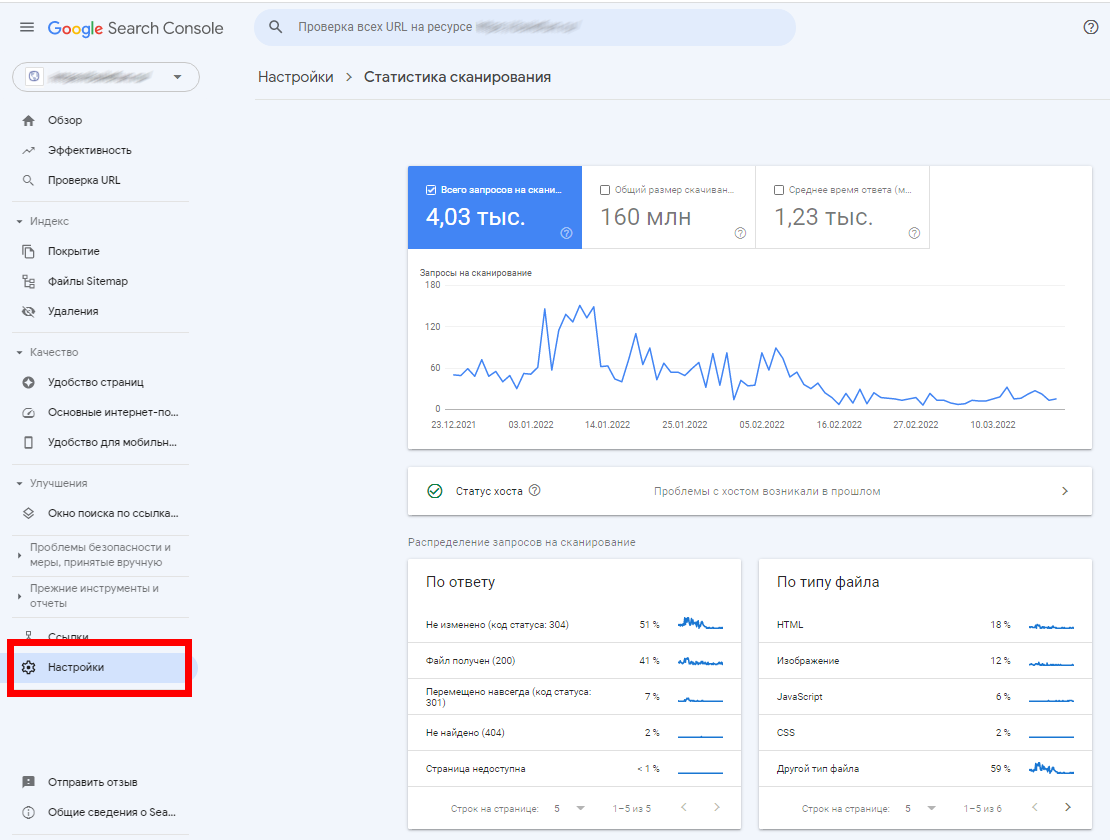
Учитываются и повторные запросы сканирования одного и того же URL. Кроме того, у каждой поисковой машины существуют
ограничения по уровням доступа, а также по размеру текстового контента.
По всем вышеуказанным причинам сайт, особенно если он имеет сложную структуру и большое количество страниц, не может
быть проиндексирован за один раз (и даже за 2-3-4).
Crawlspider¶
- classscrapy.spiders.CrawlSpider¶
Это наиболее часто используемый паук для сканирования обычных веб-сайтов, т. к. он обеспечивает удобный механизм перехода по ссылкам путём определения набора правил. Возможно, он не лучше всего подходит для вашего конкретного веб-сайта или проекта, но он достаточно универсален для нескольких случаев, поэтому вы можете начать с него и переопределить его по мере необходимости для получения дополнительных функций или просто реализовать свой собственный паук.
Помимо атрибутов, унаследованных от Spider (которые вы должны указать), данный класс поддерживает новый атрибут:
- rules¶
Это список из одного (или нескольких) объектов
Rule. КаждыйRuleопределяет определенное поведение при сканировании сайта. Объекты правил описаны ниже. Если несколько правил соответствуют одной и той же ссылке, будет использоваться первое в соответствии с порядком, в котором они определены в этом атрибуте.
Данный паук также предоставляет замещаемый метод:
- parse_start_url(response, **kwargs)¶
Данный метод вызывается для каждого ответа, созданного для URL-адресов в атрибуте
start_urlsпаука. Он позволяет анализировать начальные ответы и должен возвращать либо объект элемента, либо объектRequest, либо итерацию, содержащую любой из них.
Правила сканирования¶
Csvfeedspider¶
- classscrapy.spiders.CSVFeedSpider¶
Данный паук очень похож на XMLFeedSpider, за исключением того, что он выполняет итерацию по строкам, а не по узлам. На каждой итерации вызывается метод
parse_row().- delimiter¶
Строка с символом-разделителем для каждого поля в файле CSV. По умолчанию используется
','(запятая).
- quotechar¶
Строка с символом вложения для каждого поля в файле CSV. По умолчанию используется
'"'(кавычки).
Список имён столбцов в файле CSV.
- parse_row(response, row)¶
Получает ответ и текст (представляющий каждую строку) с ключом для каждого предоставленного (или обнаруженного) заголовка CSV-файла. Данный паук также дает возможность переопределить методы
adapt_responseиprocess_resultsдля целей предварительной и постобработки.
Пример CSVFeedSpider¶
Давайте посмотрим на пример, аналогичный предыдущему, но с использованием CSVFeedSpider:
Scrapy.spider¶
- classscrapy.spiders.Spider¶
Xmlfeedspider¶
- classscrapy.spiders.XMLFeedSpider¶
XMLFeedSpider разработан для синтаксического анализа XML-фидов путём их итерации по определенному имени узла. Итератор можно выбрать из:
iternodes,xmlиhtml. Рекомендуется использовать итераторiternodesпо соображениям производительности, поскольку итераторыxmlиhtmlгенерируют сразу всю DOM для её анализа. Однако использованиеhtmlв качестве итератора может быть полезно при парсинге XML с плохой разметкой.Чтобы установить итератор и имя тега, необходимо определить следующие атрибуты класса:
- iterator¶
Строка, определяющая используемый итератор. Это может быть и то, и другое:
По умолчанию:
'iternodes'.
- itertag¶
Строка с именем узла (или элемента) для итерации. Пример:
- namespaces¶
Список кортежей
(prefix,uri), которые определяют пространства имён, доступные в этом документе, которые будут обрабатываться этим пауком.prefixиuriбудут использоваться для автоматической регистрации пространств имён с помощью методаregister_namespace().Затем вы можете указать узлы с пространствами имён в атрибуте
itertag.Пример:
Помимо данных новых атрибутов, у этого паука также есть следующие переопределяемые методы:
- adapt_response(response)¶
Метод, который получает ответ, как только он поступает от промежуточного программного обеспечения паука, до того, как паук начнет его анализировать. Его можно использовать для изменения тела ответа перед его анализом. Данный метод получает ответ, а также возвращает ответ (он может быть таким же или другим).
- parse_node(response, selector)¶
Данный метод вызывается для узлов, соответствующих указанному имени тега (
itertag). Получает ответ иSelectorдля каждого узла. Переопределение этого метода обязательно. Иначе у вас, паук, ничего не получится. Данный метод должен возвращать объект элемента,Requestили итерацию, содержащую любой из них.
- process_results(response, results)¶
Данный метод вызывается для каждого результата (элемента или запроса), возвращаемого пауком, и он предназначен для выполнения любой последней обработки, необходимой перед возвратом результатов в ядро фреймворка, например, установка идентификаторов элементов. Он получает список результатов и ответ, который вызвал данные результаты. Он должен возвращать список результатов (элементов или запросов).
Пример XMLFeedSpider¶
Данные пауки довольно просты в использовании, давайте рассмотрим один пример:
По сути, мы создали паука, который загружает фид из заданного start_urls, а затем выполняет итерацию по каждому из своих тегов item, распечатывает их и сохраняет некоторые случайные данные в Item.
Аргументы паука¶
Пауки могут получать аргументы, изменяющие их поведение. Некоторые распространенные варианты использования аргументов паука — определение начальных URL-адресов или ограничение сканирования определенными разделами сайта, но их можно использовать для настройки любых функций паука.
Аргументы паука передаются через команду crawl с использованием параметра -a. Например:
Пауки могут получить доступ к аргументам в своих методах __init__:
По умолчанию метод __init__ принимает любые аргументы паука и копирует их в паук как атрибуты. Приведённый выше пример также можно записать следующим образом:
Если вы запускаете Scrapy из скрипта, вы можете указать аргументы паука при вызове CrawlerProcess.crawl или CrawlerRunner.crawl:
Имейте в виду, что аргументы паука — это всего лишь строки. Паук не будет выполнять парсинг сам по себе. Если бы вам нужно было установить атрибут start_urls из командной строки, вам пришлось бы самостоятельно проанализировать его в список, используя что-то вроде ast.literal_eval() или json.loads(), а затем установить его как атрибут.
Вежливые и вредные роботы
Классификация не официальная, но вполне подходящая в данном случае.
Не стоит думать, что объем трафика, генерируемого роботами, ничтожен: поисковые роботы есть не только у Google и
«Яндекса», а также других поисковых систем, но и у огромного количества аналитических сервисов, сервисов
статистики, SEO-инструментов. Например, существуют: Alexa, Amazon, Xenu, NetPeak, SEranking.
Поисковые роботы указанных сервисов в некоторых случаях — например, при сверхограниченных ресурсах сервера
— могут становиться настоящей проблемой. Часто вебмастеры сталкиваются и с откровенно вредоносными
краулерами, которые постоянно добывают определенный тип данных: например, электронные адреса для создания баз данных
для организации дальнейших почтовых рассылок.
Зачем поисковые роботы притворяются реальными пользователями
Краулеры поисковых систем почти всегда «играют по правилам». Они никогда не представляются
пользовательским клиентом — например, браузером. Однако пауки различных сервисов сканируют огромные
массивы данных. Если они будут соблюдать все ограничения для краулеров (бюджеты обращений, интервалы между
обращениями), скорость сканирования будет оставаться очень низкой.
Чтобы решить эту проблему, разработчики веб-сервисов в частном порядке создают пауков, которые представляются
пользовательским клиентом, чаще всего — браузером.
Как работает робот google и «яндекса»
Если представить алгоритм взаимодействия поискового робота со страницей обобщенно, оно выглядит следующим образом:
- Переход по URL.
- Сканирование контента страницы.
- Сохранение содержимого на сервере. На этом этапе может происходить конвертация формата данных в удобочитаемый
для поисковой машины формат. - Повторение указанной цепочки с переходом по новому URL.
Как часто обновляется индекс google и «яндекса»
Информация о найденных ссылках попадает в базы данных поисковых машин не сразу, а через определенный период времени.
Обновление индекса — базы данных, содержащей ссылки на вновь найденные URL — у «Яндекса»
может занимать от нескольких дней до 1–2 недель. Google же обновляет индекс гораздо чаще — несколько раз
за сутки.
Это, пожалуй, одно из самых принципиальных отличий между двумя поисковыми системами именно с точки зрения процессов
обработки новых страниц.
Пример crawlspider¶
Давайте теперь посмотрим на пример CrawlSpider с правилами:
importscrapyfromscrapy.spidersimportCrawlSpider,Rulefromscrapy.linkextractorsimportLinkExtractorclassMySpider(CrawlSpider):name='example.com'allowed_domains=['example.com']start_urls=['http://www.example.com']rules=(# Extract links matching 'category.php' (but not matching 'subsection.php')# and follow links from them (since no callback means follow=True by default).Rule(LinkExtractor(allow=('category.php',),deny=('subsection.php',))),# Extract links matching 'item.php' and parse them with the spider's method parse_itemRule(LinkExtractor(allow=('item.php',)),callback='parse_item'),)defparse_item(self,response):self.logger.info('Hi, this is an item page! %s',response.url)item=scrapy.Item()item['id']=response.xpath('//td[@id="item_id"]/text()').re(r'ID: (d )')item['name']=response.xpath('//td[@id="item_name"]/text()').get()item['description']=response.xpath('//td[@id="item_description"]/text()').get()item['link_text']=response.meta['link_text']url=response.xpath('//td[@id="additional_data"]/@href').get()returnresponse.follow(url,self.parse_additional_page,cb_kwargs=dict(item=item))defparse_additional_page(self,response,item):item['additional_data']=response.xpath('//p[@id="additional_data"]/text()').get()returnitemПример csvfeedspider¶
Давайте посмотрим на пример, аналогичный предыдущему, но с использованием CSVFeedSpider:
Пример xmlfeedspider¶
Данные пауки довольно просты в использовании, давайте рассмотрим один пример:
По сути, мы создали паука, который загружает фид из заданного start_urls, а затем выполняет итерацию по каждому из своих тегов item, распечатывает их и сохраняет некоторые случайные данные в Item.
Примеры sitemapspider¶
Самый простой пример: обработать все URL-адреса, обнаруженные через карты сайта, с помощью обратного вызова parse:
Обработать некоторые URL-адреса с определенным обратным вызовом и другие URL-адреса с другим обратным вызовом:
Ссылки
Как только страница обновилась в Википедии она обновляется в Вики 2.Обычно почти сразу, изредка в течении часа.
Универсальные пауки¶
Scrapy поставляется с некоторыми полезными универсальными пауками, которые вы можете использовать для создания подклассов своих пауков. Их цель — предоставить удобные функции для нескольких распространенных случаев парсинга, таких как переход по всем ссылкам на сайте на основе определенных правил, сканирование с Sitemaps.xml или парсинг фида XML/CSV.
Для примеров, используемых в следующих пауках, мы предполагаем, что у вас есть проект с TestItem, объявленным в модуле myproject.items:
Фактор роботности
До недавнего времени поисковые роботы, которые притворяются реальными пользователями, могли негативным образом влиять
на статистику посещаемости сайта, искажая ее. Сегодня фактор роботности учитывает как Google Analytics, так и «Яндекс.Метрика».
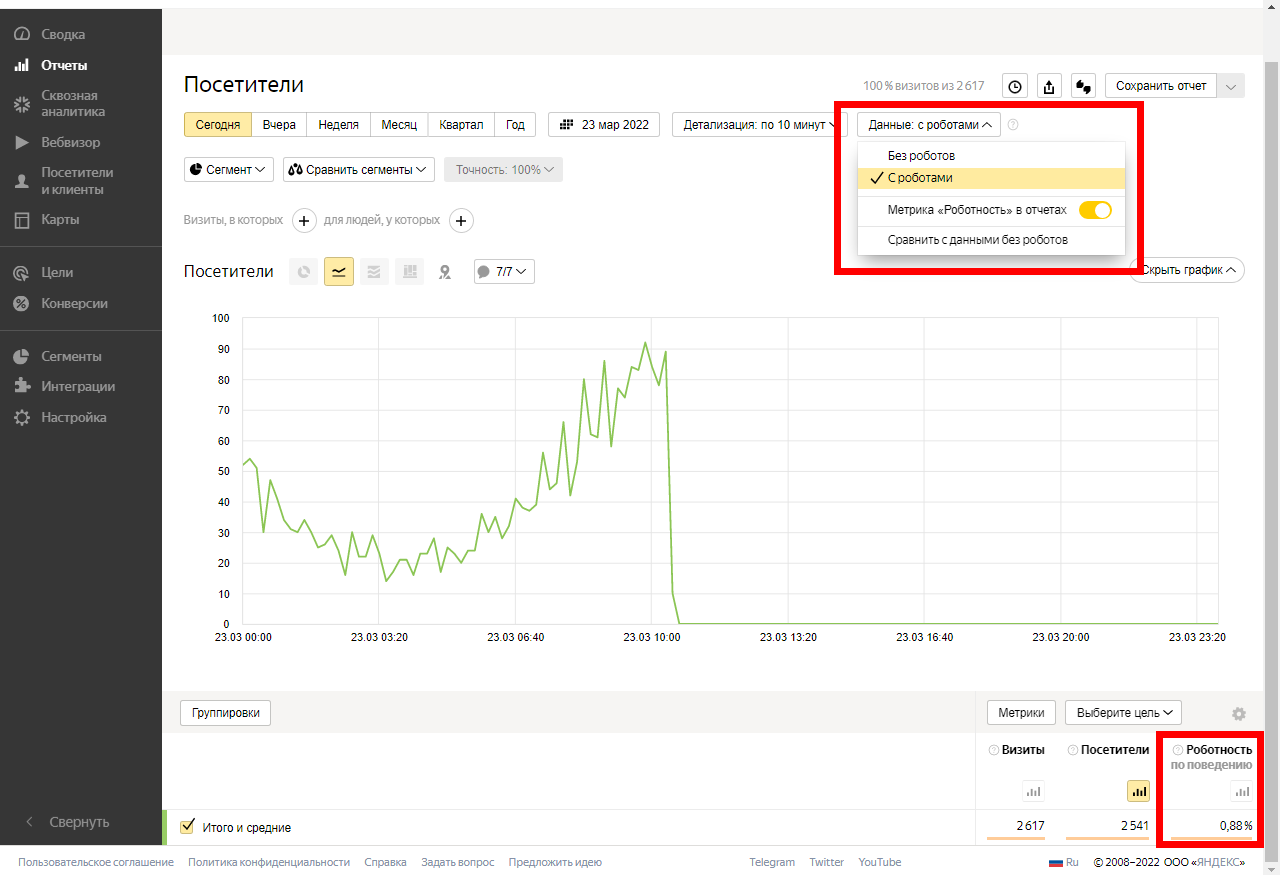
В любом отчете «Яндекс.Метрики» можно ограничить отображение визитов, создаваемых роботами. Для этого откройте
любой интересующий вас отчет, кликните по строке «Данные с роботами» и выберите необходимый сценарий
фильтрации:
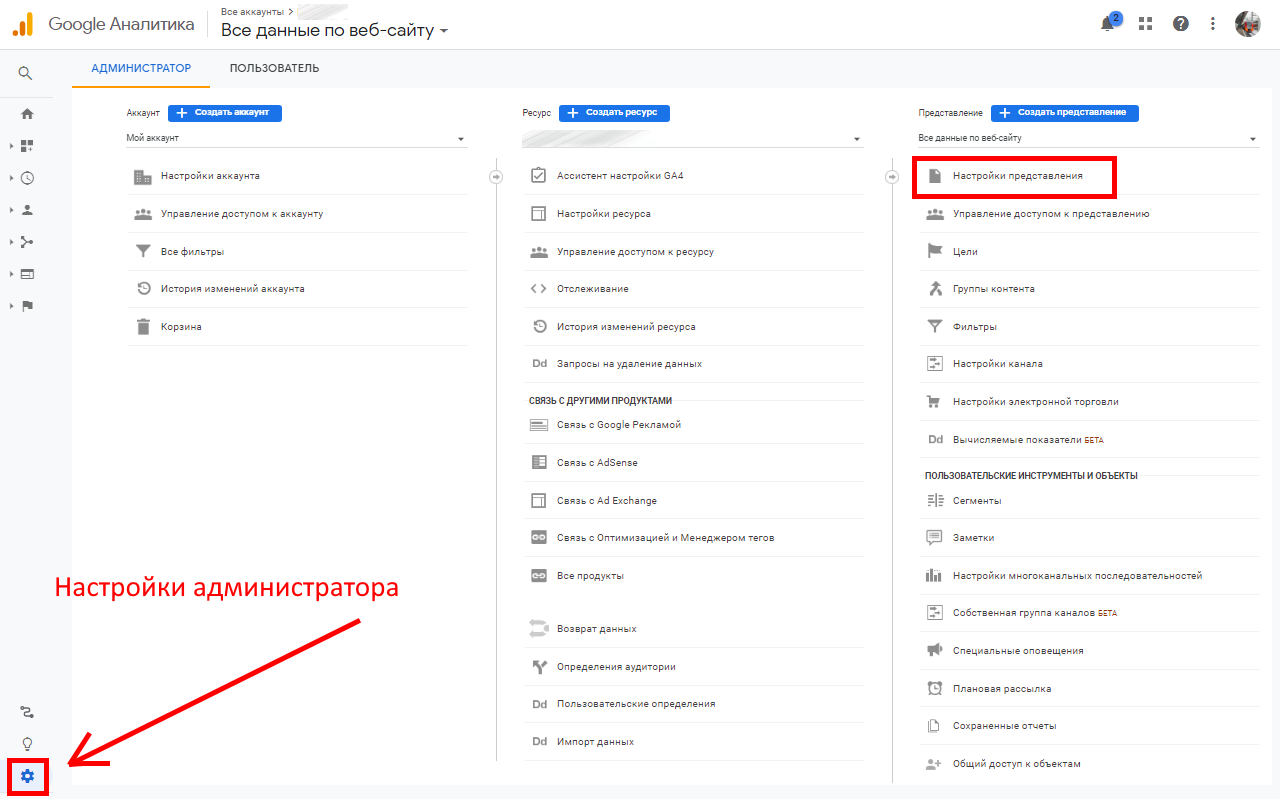
В Google Analytics также можно фильтровать роботов. Для этого откройте настройки администратора и перейдите в
параметры представления:
Сделайте активным чекбокс «Исключить обращения роботов и пауков»:
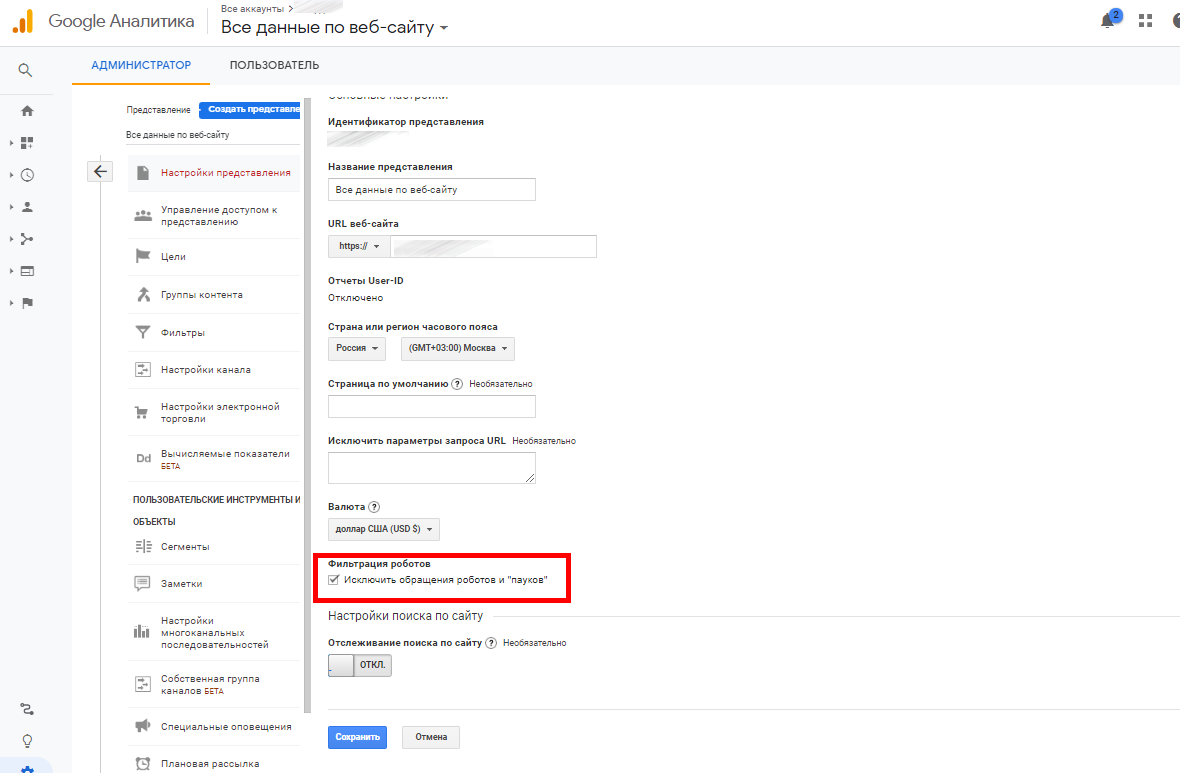
Всё. Теперь GA не будет учитывать их своих отчетах.


, цена 4600 руб")




